

背景



訓練神經(jīng)網(wǎng)絡(luò)執(zhí)行各種任務,例如識別物體、導航無人駕駛汽車、玩游戲,不僅會帶來很高的計算功耗,也會花費很長時間。集成了成百上千個處理器的大型計算機通常需要學習這些任務,而訓練時間會達到幾周甚至數(shù)月。
那么,為什么會出現(xiàn)上述現(xiàn)象呢?
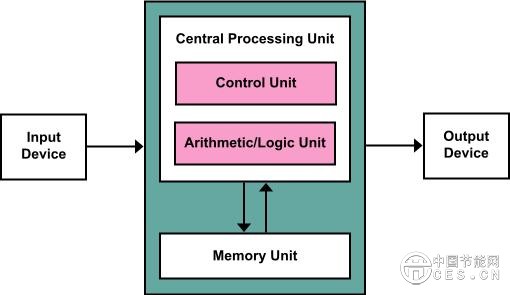
究其原因,還是要從經(jīng)典的計算機體系結(jié)構(gòu):馮·諾依曼體系結(jié)構(gòu)說起。馮·諾依曼體系結(jié)構(gòu)是目前大多數(shù)計算機以及處理器芯片的主流架構(gòu)。這種計算機體系結(jié)構(gòu)是由美籍匈牙利科學家馮·諾依曼(John von Neumann)于1946年提出。
(圖片來源:維基百科)
在馮·諾依曼體系結(jié)構(gòu)中,存儲器(內(nèi)存)用于存儲程序指令和數(shù)據(jù);處理器(CPU)則用于執(zhí)行指令與處理相關(guān)數(shù)據(jù)。然而,處理器與內(nèi)存是完全分離的兩個單元,數(shù)據(jù)需要在處理器與內(nèi)存之間來回移動。隨著計算機技術(shù)不斷進步,處理器速度不斷提高,內(nèi)存容量也不斷擴大,可是內(nèi)存訪問速度的增長卻緩慢,成為了計算機整體性能的一個重要瓶頸,也就是所謂的“內(nèi)存墻”問題。
采用馮·諾依曼體系結(jié)構(gòu)的計算機,在訓練神經(jīng)網(wǎng)絡(luò)時,需要展開大量計算,頻繁讀寫內(nèi)存,數(shù)據(jù)會在處理器與內(nèi)存之間頻繁地來回往復,這樣會耗費大部分的能量與時間。
為了解決上述問題,“內(nèi)存內(nèi)計算(in-memory computing)”提供了一種非常有前途的解決方案。它在同一個器件上集成存儲與計算功能,讓內(nèi)存不僅成為存儲器,也成為處理器。這樣一來,在內(nèi)存中直接執(zhí)行計算任務,大大提升計算機的整體性能與效率,大幅降低能耗,加快運行速度。
近年來,世界各國的科學家們展開了許多有望帶來“內(nèi)存內(nèi)計算”的科研探索。筆者曾多次介紹過相關(guān)領(lǐng)域的科研突破,讓我們先通過以“憶阻器”與“阻變式樣存儲器”為代表的科研案例來回顧一下:
(一)美國密西根大學的研究人員開發(fā)出一種新型憶阻器芯片,它能突破傳統(tǒng)計算機體系結(jié)構(gòu)所遭遇的瓶頸,更加適合人工智能機器學習系統(tǒng),更好地應對復雜的大數(shù)據(jù)問題,功耗更低,速度更快。
(圖片來源:密西根大學)
(二)法國國家科學研究院、波爾多大學與埃夫里大學的研究人員們聯(lián)合開發(fā)出一種直接位于芯片上的人工神經(jīng)突觸,也稱為“憶阻器”。這一研究成果讓智能系統(tǒng)學習所需的時間與能量變得更少,并且是全自動的。
(圖片來源: 法國國家科學研究院)
(三)美國密歇根大學開發(fā)出由憶阻器制成的神經(jīng)網(wǎng)絡(luò)系統(tǒng),也稱為儲備池計算系統(tǒng)。它教會機器像人類一樣思考,并顯著提升效率。它可以避免大多數(shù)昂貴的訓練過程,也為網(wǎng)絡(luò)提供了記憶能力。
(圖片來源:參考資料【2】)
(四)美國斯坦福大學團隊曾開發(fā)出一種“三維芯片”,將存儲器和邏輯單元,像樓板一樣一層一層地交替放置,并采用成千上萬的垂直納米連接進行通信。這樣縮短了數(shù)據(jù)傳輸?shù)木嚯x,讓數(shù)據(jù)傳輸?shù)酶?,使用的電量更少?/div>
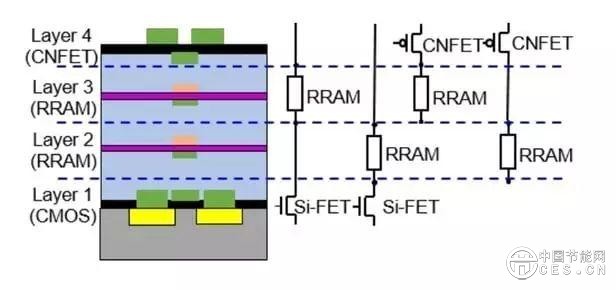







(圖片來源:斯坦福大學)
(五)美國普渡大學、國家標準與技術(shù)研究院以及泰斯研究公司的研究人員們合作設(shè)計出由二維材料二碲化鉬制成的阻變式存儲器(RRAM)。這種 RRAM 有望提供高速且省電的數(shù)據(jù)存儲方式。
下圖所示:基于2H-MoTe2- 和 2H-Mo1−xWxTe2- 的 RRAM 的表現(xiàn)以及根據(jù)薄片的厚度設(shè)置的電壓。
(圖片來源:參考資料【3】)
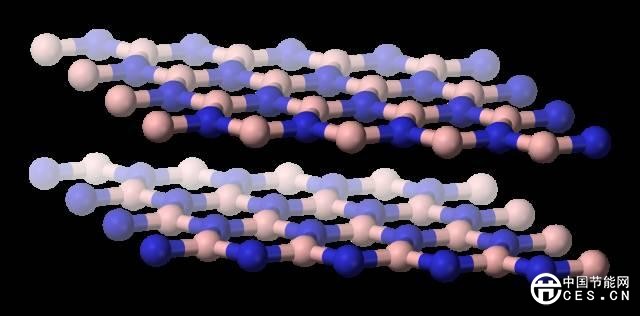
(六)中國蘇州大學的研究人員多層六方氮化硼作為電介質(zhì),設(shè)計了一組“阻變式存儲器(RRAM)”。這項研究有望帶來比目前存儲技術(shù)更加快速與節(jié)能的新存儲技術(shù)。
六方氮化硼結(jié)構(gòu)示意圖(圖片來源:維基百科)
(七)俄羅斯莫斯科物理技術(shù)學院(MIPT)的科研人員開發(fā)出一種新方案,能控制由原子層沉積(ALD)技術(shù)制備的鉭氧化物薄膜中的氧含量,這種薄膜有望成為非易失性阻變式存儲器的基礎(chǔ)。
(圖片來源:MIPT)
創(chuàng)新
今天,讓我們來看一項有望帶來“內(nèi)存內(nèi)計算”的新成果。
近日,美國加州大學圣迭戈分校的科研團隊開發(fā)出一種神經(jīng)啟發(fā)的軟硬件協(xié)同設(shè)計方案,這一方案將使得神經(jīng)網(wǎng)絡(luò)訓練更加節(jié)能與快速。有朝一日,他們的工作將使得在低功耗設(shè)備例如智能手機、筆記本和嵌入式設(shè)備上訓練神經(jīng)網(wǎng)絡(luò)變得可能。
下圖所示:加州大學圣迭戈分校的一個科研團隊開發(fā)的硬件與算法,將降低訓練神經(jīng)網(wǎng)絡(luò)所需要的能耗與運行時間。
(圖片來源:David Baillot/加州大學圣迭戈分校雅各布斯工程學院)
一篇近期發(fā)表在《自然通信(Nature Communications)》期刊上的論文描述了這項研究進展。
技術(shù)
加州大學圣迭戈分校雅各布斯工程學院電氣與計算工程系教授、論文高級作者 Duygu Kuzum 及其實驗室與 Adesto Technologies 公司合作開發(fā)出“可在內(nèi)存單元中直接進行計算”的硬件與算法,無需反復地來回傳遞數(shù)據(jù)。
加州大學圣迭戈分校 Kuzum 研究小組的電氣工程系博士生、論文第一作者 Yuhan Shi 表示:“我們正在從兩端(設(shè)備端與算法端)解決這一問題,最大化神經(jīng)網(wǎng)絡(luò)訓練時的能量效率。”
這項研究所用的硬件組件,是一種超級節(jié)能的非易失性存儲器技術(shù),即512千比特亞量子“導電橋式隨機存取存儲器(CBRAM)”陣列。
亞量子導電橋式隨機存取存儲器特性(圖片來源:參考資料【4】)
CBRAM,是一種極具潛力的電阻式存儲器技術(shù),主要是利用記憶元件電阻之大小作為信息儲存狀態(tài)判讀之依據(jù),不同的電阻代表不同的儲存狀態(tài),它在存取速度及能耗表現(xiàn)上具有極佳的表現(xiàn),被視為最有潛力成為下一世代的非揮發(fā)性存儲器元件之一。
(圖片來源:加州大學圣迭戈分校雅各布斯工程學院)
亞量子導電橋式隨機存取存儲器陣列的功耗是如今領(lǐng)先的存儲器技術(shù)的百分之一到十分之一。這種器件基于 Adesto 的 CBRAM 存儲技術(shù)。這種技術(shù)主要用作只具有 “0”與“1”兩種狀態(tài)的數(shù)字存儲器,但是 Kuzum 及其實驗室的演示表明,這項技術(shù)可以通過編程而具有多個模擬狀態(tài),從而模仿人腦中的生物突觸。這種所謂的“突觸裝置”能用于為神經(jīng)網(wǎng)絡(luò)訓練展開“內(nèi)存內(nèi)計算”。
Kuzum 在加州大學圣迭戈分校機器集成計算與安全中心工作,她領(lǐng)導開發(fā)了可簡單映射到這種神經(jīng)突觸器件陣列上的算法。在神經(jīng)網(wǎng)絡(luò)計算期間,這種算法節(jié)約了較多的能量與時間。
下圖所示:從左到右,加州大學圣迭戈分校電氣工程系博士生、論文第一作者 Yuhan Shi 以及加州大學圣迭戈分校電氣與計算工程系教授、研究帶頭人 Duygu Kuzum。
(圖片來源:加州大學圣迭戈分校雅各布斯工程學院)
該方案使用了一種節(jié)能的神經(jīng)網(wǎng)絡(luò),稱為“脈沖神經(jīng)網(wǎng)絡(luò)(spiking neural network)”,用于實現(xiàn)硬件中的無監(jiān)督學習。最重要的是,Kuzum 的團隊應用了另一種由他們開發(fā)的節(jié)能算法,稱為“軟剪枝(soft-pruning)”,它使神經(jīng)網(wǎng)絡(luò)訓練更加節(jié)能,也不會在準確度上犧牲很多。
節(jié)能算法
神經(jīng)網(wǎng)絡(luò)是一系列互連的人工神經(jīng)元層,每一層的輸出為另一層提供輸入。這些層之間連接的強度由所謂的“權(quán)重”代表。訓練神經(jīng)網(wǎng)絡(luò)能對這些權(quán)重進行更新。
傳統(tǒng)神經(jīng)網(wǎng)絡(luò)耗費許多能量來持續(xù)更新每一個權(quán)重。但是,在脈沖神經(jīng)網(wǎng)絡(luò)中,只有與脈沖神經(jīng)元相關(guān)聯(lián)的權(quán)重才會得到更新。這意味著更少的更新,也意味著更少的計算功耗和時間。
神經(jīng)網(wǎng)絡(luò)也展開所謂的“無監(jiān)督學習”。“無監(jiān)督學習”意味著它可以從根本上進行自我訓練。例如,如果將一系列手寫數(shù)字展示給神經(jīng)網(wǎng)絡(luò),神經(jīng)網(wǎng)絡(luò)將搞清楚如何區(qū)分0、1、2等。這么做的好處是,神經(jīng)網(wǎng)絡(luò)無需通過標記的樣本來訓練,意味著它無需被告知它正看到 0、1、2,這對于導航等自主應用來說很有用。
為了訓練得更快更節(jié)能,Kuzum 實驗室開發(fā)出一種新算法,他們稱為“軟剪枝”,配合無監(jiān)督的脈沖神經(jīng)網(wǎng)絡(luò)。“軟剪枝”,是一種可以找到在訓練期間已經(jīng)成熟的權(quán)重,然后將它們設(shè)置為非零常數(shù)。這樣就阻止了它們在剩余的訓練中繼續(xù)更新,從而最小化計算功率。
“軟剪枝”,不同于傳統(tǒng)的剪枝方法,因為它是在訓練期間實現(xiàn)的,而不是在訓練之后。當神經(jīng)網(wǎng)絡(luò)將它的訓練放在測試中時,“軟剪枝”也能帶來更高的準確度。通常在剪枝中,冗余或者不重要的權(quán)重會被完全刪除掉。負面影響是,你修剪的權(quán)重越多,神經(jīng)網(wǎng)絡(luò)在測試時的準確度就越低。但是“軟剪枝”卻能在低能量條件下保留住這些權(quán)重,所以它們?nèi)匀粠椭窠?jīng)網(wǎng)絡(luò)以較高的準確度執(zhí)行任務。
測試軟硬件協(xié)同設(shè)計
團隊在亞量子CBRAM 神經(jīng)突觸器件陣列上 ,實現(xiàn)了神經(jīng)啟發(fā)的無監(jiān)督脈沖神經(jīng)網(wǎng)絡(luò)以及“軟剪枝”算法。然后,他們訓練這種神經(jīng)網(wǎng)絡(luò)從 MNIST 數(shù)據(jù)庫中分類手寫數(shù)字。
Yuhan Shi 安裝突觸器件進行測試(圖片來源:加州大學圣迭戈分校雅各布斯工程學院)
在測試中,達75%的權(quán)重得到“軟剪枝”,神經(jīng)網(wǎng)絡(luò)分類數(shù)字準確度達93%。相比而言,采用傳統(tǒng)的修剪方法,僅40%的權(quán)重得到修剪,神經(jīng)網(wǎng)絡(luò)的準確度低于90%。
價值
Kuzum 表示:“傳統(tǒng)處理器中的片上存儲器非常有限,所以它們沒有足夠的能力在同一芯片上同時進行計算與存儲。但是,在這種方案中,我們擁有了能在存儲器中展開神經(jīng)網(wǎng)絡(luò)訓練相關(guān)計算的大容量存儲器陣列,無需將數(shù)據(jù)傳輸至外部處理器。在訓練期間,這將帶來許多性能增益并降低能耗。”
就節(jié)能而言,團隊估計,相比于目前工藝水平,他們的神經(jīng)啟發(fā)軟硬件協(xié)同方案能最終消減神經(jīng)網(wǎng)絡(luò)訓練器件的能耗達兩到三個數(shù)量級。
Kuzum 表示:“如果我們參照其他相似的存儲技術(shù)來檢測新硬件,我們估計我們器件的能耗能降低到百分之一至十分之一,然后我們的協(xié)同設(shè)計算法又將能耗再降低到十分之一??偟膩碚f,我們希望遵循我們的方法,將能耗降低到千分之一至百分之一。”
未來
展望未來,Kuzum 和她的團隊計劃與存儲技術(shù)公司合作,將這項工作推進到下一階段。
他們的最終目標是開發(fā)一個完整系統(tǒng),在這個完整系統(tǒng)中,神經(jīng)網(wǎng)絡(luò)可以在存儲器中得到訓練,從而以更低的功耗與更少的時間預算,完成更復雜的任務。
更多>同類技術(shù)




